網站首頁 編程語言 正文
0. 前言
深度學習分布式訓練任務,就是由多個進程一起協作完成某個模型的訓練,這些進程可以運行在單個機器上,也可以運行在多個機器上;可以運行在 CPU Device(設備)上,也可以運行在 GPU、NPU(華為昇騰)、XPU(百度昆侖) Device 上;可以運行在 Host(物理機) 上,也可以運行在 Container(容器)、VM(虛擬機)上。那么,相比于單體訓練,分布式訓練能帶來哪些好處呢?分布式進程是如何啟動的呢?這些進程之間需要交互嗎?如何給每個進程分配訓練任務?本文將帶你來一起尋找這些問題的答案。
1. 深度學習如何選擇分布式訓練框架?
大模型帶來的挑戰主要有兩點:海量樣本、參數(萬億級別)和較長的收斂時間。一般來說,單張 GPU A100 顯存大小 40G、單臺華為 2288H V5 的內存大小能達到上百 G,所以大模型的訓練得借助多機多卡,但是隨著機器數的增加,收益卻不能帶來線程增長,這主要是機器間通信開銷指數增加,分布式訓練還得保證一定的多卡加速比。
大模型主要分為兩類:一是搜索、推薦、廣告類任務,它的特點是海量樣本及大規模稀疏參數(sparse embeddings),適合使用 CPU/GPU 參數服務器模式(PS);另一種是 CV、NLP 任務,它的特點是常規樣本數據及大規模稠密參數,它適合用純 GPU 集合通信模式(Collective)。參數服務器模式從第一代 Alex Smola 在 2010 年提出的 LDA(文本挖掘領域的隱狄利克雷分配模型),到第二代 Jeff Dean 提出的 DistBelief,接著到第三代李沐提出的相對成熟的現代 Parameter Server 架構,再到后來的百花齊放:Uber 的 Horvod,阿里的 XDL、PAI,Meta 的 DLRM,字節的 BytePs、美團基于 Tensorlow 做的各種適配等等。參數服務器的功能日趨完善,性能也越來越強,有純 CPU、純 GPU,也有異構模式。另一方面,基于純 GPU 的集合通信模式的分布式訓練框架,伴隨著 Nvidia 的技術迭代,特別是 GPU 通信技術(GPU Direct RDMA)的進步,性能也變得愈來愈強。
AI 模型訓練任務流程:初始化模型參數 -> 逐條讀取訓練樣本 -> 前向、反向、參數更新 -> 讀取下一條樣本 -> 前向、反向、參數更新 -> … 循環,直至收斂。
在軟件層面的體現就是計算機按順序運行一個個 OP(計算單元,可以理解為函數)。假如一個大模型的 OP 總數為n,第 i個 OP 的輸入、輸出變量、參數、優化器中間狀態變量個數總共為mi ,訓練單條樣本需要的算力為 ci Flops(浮點運算次數),那么需要存儲的累計變量個數為 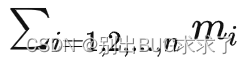
,所需總算力為 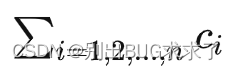
,同時考慮到不同 OP 之間的存儲、算力需求差異很大,比如有的 OP 需要消耗巨大的存儲能力,卻只要很少的算力,而有的 OP 需要巨大的算力,卻對存儲的要求很低。第i個 OP 和第j 個OP 之間的通信開銷(帶寬和時延)標識為k_i,j . 從數學上看,如果給定固定數量的 CPU、GPU 機器卡數,那么在存儲資源利用率λ、算力資源利用率η 、最短訓練時間γ等指標上通過凸優化理論可以取得(近似)最優解。
然而,即使從數學原理上求出了最優的參數和 OP 放置策略,從工程實踐上看,實現復雜度非常高且幾乎無法復用(對于一個新來的大模型),這是由深度學習框架的實現原理決定的。我們再來看看市面上已有的分布式策略,比如:
- 數據并行:最容易理解,海量訓練樣本切分到不同機器上,傳統的參數服務器模式是典型代表
- 模型并行:把模型本身進行切分,使得每臺機器(顯卡)上只需要存模型的一部分,實現方式多種多樣:
- 只切分模型參數
- 只做模型的簡單橫向切分,一個 Layer 切成多個 Partition
- 對一個算子進行拆分,比如 FC(全連接層),把參數和計算的切分到多個GPU上,通過通信完成這個原子計算
- 流水線并行:老生常談了,通過劃分 micro batch 讓計算機在通信的時候不要停止計算
- Sharding:可以理解為是比較易用的模型并行,主要是參數、梯度、優化器狀態切分到不同機器(顯卡)
- Offload:巨量稀疏參數卸載到 SSD、Host 內存、HBM(顯存)等,采用多級存儲架構;而對于稠密參數,則需要借用混合精讀
- Recompute:用時間換空間的思想,即在前向時只保存部分中間結果,在反向時重新計算沒保存的部分
混合并行:上述能用的并行策略全用上
上述這些并行策略有哪些特點呢?比較容易想到,但是實施起來,有一定開發量且難以復用。這里,我再補充一條,就是 C++ 軟件層面本身的性能優化,涉及到代碼優化、執行流程優化、iCache、iTable、PGO 等優化,預計在訓練速度上至少有 10% 的提升,而且對每個模型基本都有效。但是,很少看到有人這樣干過。一方面原因是相比于宏觀層面的并行策略能帶來巨大的性能提升,這部分的性能提升點顯得很小;另一方面原因,也可能是能夠做到軟件性能極致優化(結合操作系統和編譯器)的專業人才在 AI 領域是稀缺的。
從個人經驗來看,如果按數學上最優的策略來執行分布式訓練任務,能帶來大約 30% 的成本降低和碳排放(對應的絕對成本降低可大了去了),能節省巨大的人力開發成本,而且使得模型能夠快速收斂、上線并快速迭代。想要達成這一目標,我們要從哪些方向著手呢?這里先賣個關子,先看看現有的分布式訓練框架的運行機制。
2. 深度學習分布式訓練框架的運行機制
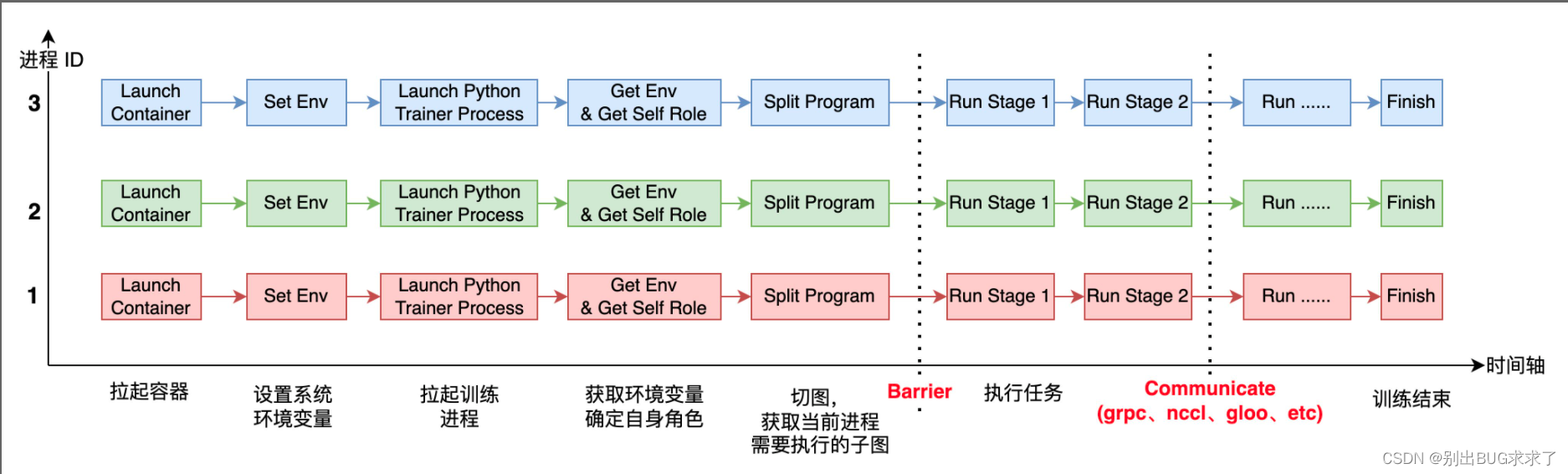
上圖表示的是 3 個進程(運行在容器里)一起協作來完成 AI 模型的分布式訓練。
每個進程啟動后,它需要感知自己全局的進程數( world_size)及自身的進程 ID(或者 rank_id),由于每個進程上運行的都是同一份訓練腳本,所以得事先在每個進程所在的系統上設置不同的環境變量,進程運行起來之后,就可以獲取環境變量,從而確定自己的角色(Worker、PServer、Coordinator 等)及rank_id、world_size 等信息。
在運行過程中,還有兩個重要的環節是 Barrier 和 Communicate. Barrier 的目的是為了實現進程間同步,比較成熟的開源項目有 gloo、mpi 等。Communicate 操作就是實現通信,滿足進程間數據交換需求。通信可以在同類型硬件之間發生,比如 CPU 到 CPU、GPU 到 GPU,也可以發生在不同硬件之間,比如 GPU 到 CPU,通信后端也有多種形式,比如 grpc、nccl、socket 等。
3. 深度學習分布式訓練框架的理想形態
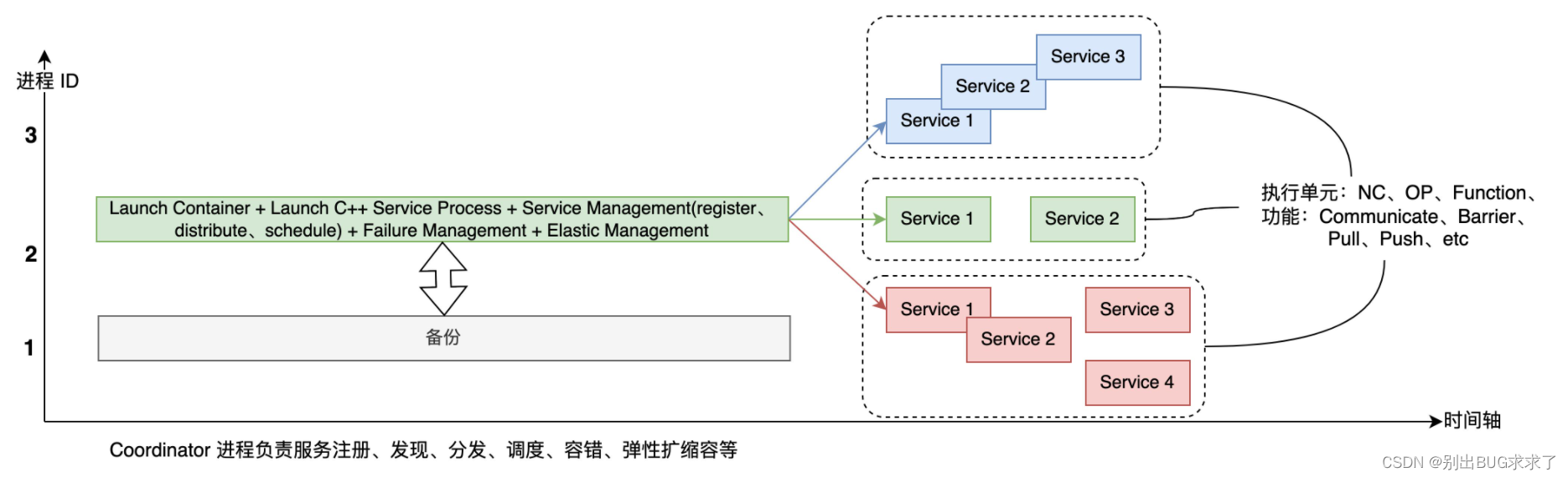
上一節中提到的深度學習分布式框架是當前主流的實現,如 Tesorflow、Pytorch、Paddle 等,它的一大優點是開發起來比較容易,能快速部署。然而,它的擴展性較差,也無法滿足最優的調度部署要求。于是,參考云原生的架構,這里我提出了分布式訓練框架的一種理想形態(上圖)。同一種顏色的服務運行在同一個進程里,它們可以是順序執行,也可以是并行執行的,可以運行在協程上,也可以運行在線程里,可以采用"去中心化"或者是"有中心化"的基于事件的調度策略。
首先,有一個集中的切圖、調度中心、服務管理模塊,用戶可以自定義各種切圖策略、調度算法及服務管理策略。其次,訓練任務完全微服務化(Service),從執行單元上來看,這里的 Service 可以是 Nerual Cell(OP 之上的概念,比如一個 Encoder、Decoder 模塊),也可以是 OP,還可以是其他 Function(函數);從功能上來說,這些 Service 可以是通信相關、Barrier 相關、也可以是 Push、Pull 相關。那么從當前的深度學習分布式訓練框架演進到下一代,需要做哪些工作呢?
- 框架的運行大腦 - Coordinator
- 自動切圖策略,這里包括一些具體的優化算法,如 allreduce fuse 等
- C++ 后端代碼服務化,去耦合,無狀態改造
- 統一的通信前端接口,支持多樣的后端
用戶在提交大模型的訓練任務時,只需要提供一個可用資源規格列表、訓練樣本及模型組網圖,剩下的事就可以全交給框架了。新一代的分布式深度學習訓練框架帶來的好處是顯而易見的:
- 為執行理論最優的調度策略提供了框架支持,從而最大化經濟效益
- 參數服務器模式和集合通信模式大一統
- 用戶上手成本更低、便于二次開發
- 零成本遷移云上部署
- 用戶組網時,不需要一行一行寫 OP,也可以直接組裝 Service(Python 端表示),能支持大一統之后的神經網絡架構
原文鏈接:https://blog.csdn.net/weixin_39589455/article/details/126836355
- 上一篇:沒有了
- 下一篇:沒有了
相關推薦
- 2022-07-16 如何編譯omx-bellagio以及ffmpeg插件
- 2022-07-02 C++分析構造函數與析造函數的特點梳理_C 語言
- 2023-02-18 C++中std::thread線程用法_C 語言
- 2021-12-20 使用Docker構建開發環境的方法步驟(?Windows和mac)_docker
- 2022-10-03 Docker容器/bin/bash?start.sh無法找到not?found問題解決_docker
- 2022-05-10 IDEA中報錯 “Error running ‘Application‘: Command line
- 2022-06-01 Android?BLE?藍牙開發之實現掃碼槍基于BLESSED開發_Android
- 2023-07-22 SpringBoot操作MongoDB時,對同一個字段設置多次條件
- 欄目分類
-
- 最近更新
-
- window11 系統安裝 yarn
- 超詳細win安裝深度學習環境2025年最新版(
- Linux 中運行的top命令 怎么退出?
- MySQL 中decimal 的用法? 存儲小
- get 、set 、toString 方法的使
- @Resource和 @Autowired注解
- Java基礎操作-- 運算符,流程控制 Flo
- 1. Int 和Integer 的區別,Jav
- spring @retryable不生效的一種
- Spring Security之認證信息的處理
- Spring Security之認證過濾器
- Spring Security概述快速入門
- Spring Security之配置體系
- 【SpringBoot】SpringCache
- Spring Security之基于方法配置權
- redisson分布式鎖中waittime的設
- maven:解決release錯誤:Artif
- restTemplate使用總結
- Spring Security之安全異常處理
- MybatisPlus優雅實現加密?
- Spring ioc容器與Bean的生命周期。
- 【探索SpringCloud】服務發現-Nac
- Spring Security之基于HttpR
- Redis 底層數據結構-簡單動態字符串(SD
- arthas操作spring被代理目標對象命令
- Spring中的單例模式應用詳解
- 聊聊消息隊列,發送消息的4種方式
- bootspring第三方資源配置管理
- GIT同步修改后的遠程分支
 提供CDN加速
提供CDN加速