網(wǎng)站首頁 編程語言 正文
項(xiàng)目中有幾個(gè)batch需要檢查所有的用戶參與的活動(dòng)的狀態(tài),以前是使用分頁,一頁一頁的查出來到內(nèi)存再處理,但是隨著數(shù)據(jù)量的增加,效率越來越低。于是經(jīng)過一頓搜索,了解到流式查詢這么個(gè)東西,不了解不知道,這一上手,愛的不要不要的,效率賊高。項(xiàng)目是springboot 項(xiàng)目,持久層用的mybatis,整好mybatis的版本后,又研究了一下JPA的版本,做事做全套,最后又整了原始的JDBCTemplate 版本。廢話不多說,代碼如下:
第一種方式: springboot + mybatis 流式查詢(網(wǎng)上說的有三種,我覺得下面這種最簡單,對(duì)業(yè)務(wù)代碼侵入性最小)
a) service 層代碼:
package com.example.demo.service;
import com.example.demo.bean.CustomerInfo;
import com.example.demo.mapper.UserMapper;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.cursor.Cursor;
import org.springframework.context.ApplicationContext;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.Resource;
@Slf4j
@Service
public class TestStreamQueryService {
@Resource
private ApplicationContext applicationContext;
@Resource
private UserMapper userMapper;
@Resource
private JdbcTemplate jdbcTemplate;
@Transactional
public void testStreamQuery(Integer status) {
mybatisStreamQuery(status);
}
private void mybatisStreamQuery(Integer status) {
log.info("waiting for query.....");
Cursor<CustomerInfo> customerInfos = userMapper.getCustomerInfo(status);
log.info("finish query!");
for (CustomerInfo customerInfo : customerInfos) {
//處理業(yè)務(wù)邏輯
log.info("===============>{}", customerInfo.getId());
}
}
}
需要注意的有兩點(diǎn):
1.是userMapper 返回的是一個(gè)Cursor類型,其實(shí)就是用游標(biāo)。然后遍歷這個(gè)cursor,mybatis就會(huì)按照你在userMapper里設(shè)置的fetchSize 大小,每次去從數(shù)據(jù)庫拉取數(shù)據(jù)
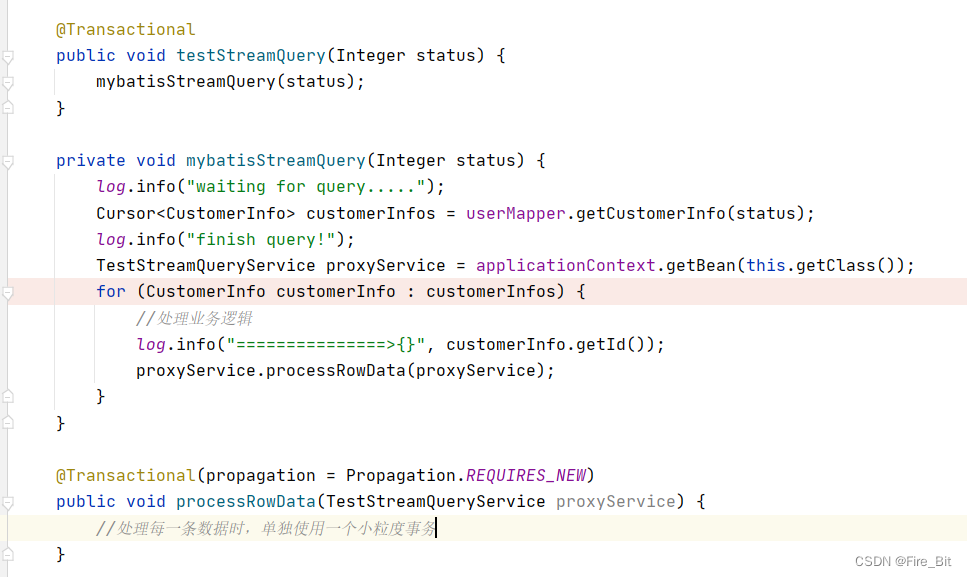
2.注意 testStreamQuery 方法上的 @transactional 注解,這個(gè)注解是用來開啟一個(gè)事務(wù),保持一個(gè)長連接(就是為了保持長連接采用的這個(gè)注解),因?yàn)槭橇魇讲樵儯看螐臄?shù)據(jù)庫拉取固定條數(shù)的數(shù)據(jù),所以直到數(shù)據(jù)全部拉取完之前必須要保持連接狀態(tài)。(順便提一下,如果說不想讓在這個(gè)testStreamQuery 方法內(nèi)處理每條數(shù)據(jù)所作的更新或查詢動(dòng)作都在這個(gè)大事務(wù)內(nèi),那么可以另起一個(gè)方法 使用required_new 的事務(wù)傳播,使用單獨(dú)的事務(wù)去處理,使事務(wù)粒度最小化。如下圖:)
b) mapper 層代碼:
package com.example.demo.mapper;
import com.example.demo.bean.CustomerInfo;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.cursor.Cursor;
import org.springframework.stereotype.Repository;
@Mapper
@Repository
public interface UserMapper {
Cursor<CustomerInfo> getCustomerInfo(Integer status);
}
mapper.xml?
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.UserMapper">
<select id="getCustomerInfo" resultType="com.example.demo.bean.CustomerInfo" fetchSize="2" resultSetType="FORWARD_ONLY">
select * from table_name where status = #{status} order by id
</select>
</mapper>
?UserMapper.java 無需多說,其實(shí)要注意的是mapper.xml中的配置:fetchSize 屬性就是上一步說的,每次從數(shù)據(jù)庫取多少條數(shù)據(jù)回內(nèi)存。resultSetType屬性需要設(shè)置為?FORWARD_ONLY, 意味著,查詢只會(huì)單向向前讀取數(shù)據(jù),當(dāng)然這個(gè)屬性還有其他兩個(gè)值,這里就不展開了。
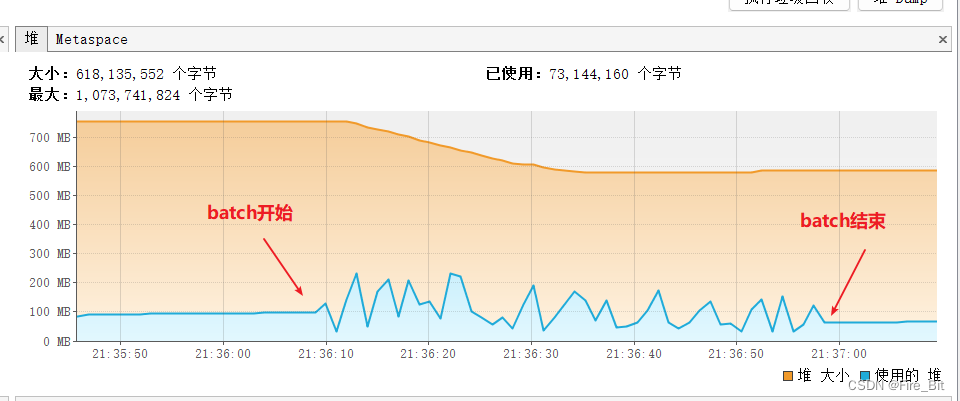
至此,springboot+mybatis 流式查詢就可以用起來了,以下是執(zhí)行結(jié)果截圖:
c)讀取200萬條數(shù)據(jù),每次fetchSize讀取1000條,batch總用時(shí)50s左右執(zhí)行完,速度是相當(dāng)可以了,堆內(nèi)存占用不超過250M,這里用的數(shù)據(jù)庫是本地docker起的一個(gè)postgre, 遠(yuǎn)程數(shù)據(jù)庫的話,耗時(shí)可能就不太一樣了
?
第二種方式:springboot+JPA 流式查詢
a)? service層代碼:
package com.example.demo.service;
import com.example.demo.dao.CustomerInfoDao;
import com.example.demo.mapper.UserMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.ApplicationContext;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.Resource;
import javax.persistence.EntityManager;
import java.util.stream.Stream;
@Slf4j
@Service
public class TestStreamQueryService {
@Resource
private ApplicationContext applicationContext;
@Resource
private UserMapper userMapper;
@Resource
private JdbcTemplate jdbcTemplate;
@Resource
private CustomerInfoDao customerInfoDao;
@Resource
private EntityManager entityManager;
@Transactional(readOnly = true)
public void testStreamQuery(Integer status) {
jpaStreamQuery(status);
}
public void jpaStreamQuery(Integer status) {
Stream<com.example.demo.entity.CustomerInfo> stream = customerInfoDao.findByStatus(status);
stream.forEach(customerInfo -> {
entityManager.detach(customerInfo); //解除強(qiáng)引用,避免數(shù)據(jù)量過大時(shí),強(qiáng)引用一直得不到GC 慢慢會(huì)OOM
log.info("====>id:[{}]", customerInfo.getId());
});
}
}
?注意點(diǎn):1. 這里的@transactional(readonly=true) 這里的作用也是保持一個(gè)長連接的作用,同時(shí)標(biāo)注這個(gè)事務(wù)是只讀的。
? ? ? ? ? ? ? ? 2. 循環(huán)處理數(shù)據(jù)時(shí)需要先:entityManager.detach(customerInfo);?解除強(qiáng)引用,避免數(shù)據(jù)量過大時(shí),強(qiáng)引用一直得不到GC 慢慢會(huì)OOM。
b) dao層代碼:
package com.example.demo.dao;
import com.example.demo.entity.CustomerInfo;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.QueryHints;
import org.springframework.stereotype.Repository;
import javax.persistence.QueryHint;
import java.util.stream.Stream;
import static org.hibernate.jpa.QueryHints.HINT_FETCH_SIZE;
@Repository
public interface CustomerInfoDao extends JpaRepository<CustomerInfo, Long> {
@QueryHints(value=@QueryHint(name = HINT_FETCH_SIZE,value = "1000"))
Stream<CustomerInfo> findByStatus(Integer status);
}
?注意點(diǎn):1.dao方法的返回值是 Stream 類型
? ? ? ? ? ? ? ? 2.dao方法的注解:@QueryHints(value=@QueryHint(name = HINT_FETCH_SIZE,value = "1000"))? 這個(gè)注解是設(shè)置每次從數(shù)據(jù)庫拉取多少條數(shù)據(jù),自己可以視情況而定,不可太大,反而得不償失,一次讀取太多數(shù)據(jù)數(shù)據(jù)庫也是很耗時(shí)間的。。。
自此springboot + jpa 流式查詢代碼就貼完了,可以happy了,下面是執(zhí)行結(jié)果:
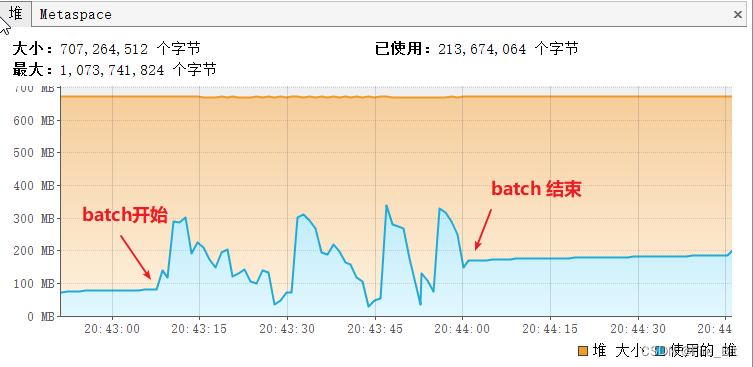
c)? batch讀取兩百萬條數(shù)據(jù),堆內(nèi)存使用截圖:
?
每次fetchSize拉取1000條數(shù)據(jù),可以看到內(nèi)存使用情況:初始內(nèi)存不到100M,batch執(zhí)行過程中最高內(nèi)存占用300M出頭然后被GC。讀取效率:不到一分鐘執(zhí)行完(處理每一條數(shù)據(jù)只是打印一下id),速度還是非常快的。
d)? 讀取每一條數(shù)據(jù)時(shí),不使用 entityManager.detach(customerInfo),內(nèi)存使用截圖:
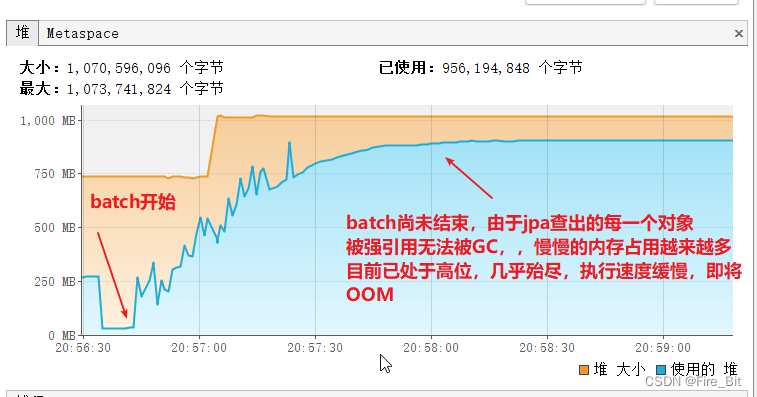
最終OOM了,這里的entityManager.detach(customerInfo) 很關(guān)鍵。
第三種方式:使用JDBC template 流式查詢
其實(shí)這種方式就是最原始的jdbc的方式,代碼侵入性很大,逼不得已也不會(huì)使用
a) 上代碼:
package com.example.demo.service;
import com.example.demo.dao.CustomerInfoDao;
import com.example.demo.mapper.UserMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.ApplicationContext;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import javax.persistence.EntityManager;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
@Slf4j
@Service
public class TestStreamQueryService {
@Resource
private ApplicationContext applicationContext;
@Resource
private UserMapper userMapper;
@Resource
private JdbcTemplate jdbcTemplate;
@Resource
private CustomerInfoDao customerInfoDao;
@Resource
private EntityManager entityManager;
public void testStreamQuery(Integer status) {
jdbcStreamQuery(status);
}
private void jdbcStreamQuery(Integer status) {
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = jdbcTemplate.getDataSource().getConnection();
conn.setAutoCommit(false);
pstmt = conn.prepareStatement("select * from customer_info where status = " + status + " order by id", ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
pstmt.setFetchSize(1000);
pstmt.setFetchDirection(ResultSet.FETCH_FORWARD);
rs = pstmt.executeQuery();
while (rs.next()) {
long id = rs.getLong("id");
String name = rs.getString("name");
String email = rs.getString("email");
int sta = rs.getInt("status");
log.info("=========>id:[{}]", id);
}
} catch (SQLException throwables) {
throwables.printStackTrace();
} finally {
try {
rs.close();
pstmt.close();
conn.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
}
b) 執(zhí)行結(jié)果:200萬數(shù)據(jù)不到50秒執(zhí)行完,內(nèi)存占用最高300M
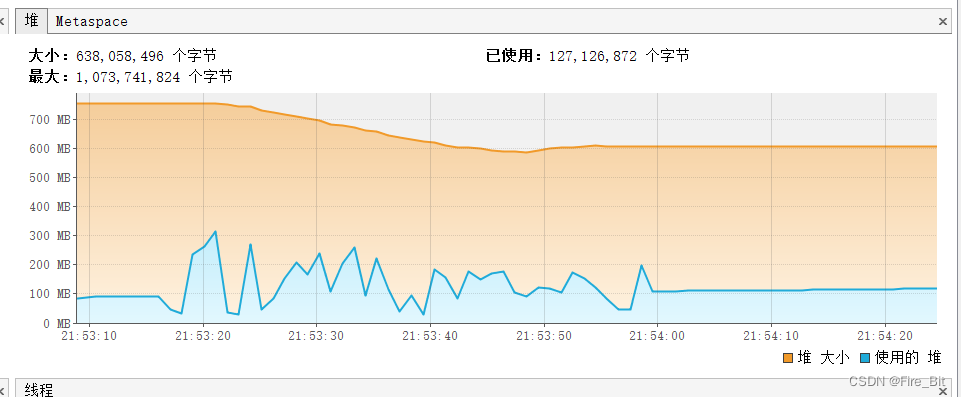
?
自此,針對(duì)不同的持久層框架,?使用不同的流式查詢,其實(shí)本質(zhì)是一樣的,歸根結(jié)底還是驅(qū)動(dòng)jdbc做事情。以上純個(gè)人見解,若有不當(dāng)之處,請(qǐng)不吝指出,共同進(jìn)步!
原文鏈接:https://blog.csdn.net/qq_43985303/article/details/130281158
- 上一篇:沒有了
- 下一篇:沒有了
相關(guān)推薦
- 2022-05-22 jQuery中的關(guān)系查找方法_jquery
- 2023-01-06 使用find命令快速定位配置文件位置_linux shell
- 2022-11-14 Swift?指針底層探索分析_Swift
- 2022-09-06 一文詳解Python如何優(yōu)雅地對(duì)數(shù)據(jù)進(jìn)行分組_python
- 2023-04-12 Pandas創(chuàng)建DataFrame提示:type?object?'object'?has?no?at
- 2022-06-22 Git?Bash終端默認(rèn)路徑的設(shè)置查看修改及拓展圖文詳解_其它綜合
- 2022-10-06 Android?Fragment源碼分析Add方法_Android
- 2023-07-02 python中編寫config文件并及時(shí)更新的方法_python
- 欄目分類
-
- 最近更新
-
- window11 系統(tǒng)安裝 yarn
- 超詳細(xì)win安裝深度學(xué)習(xí)環(huán)境2025年最新版(
- Linux 中運(yùn)行的top命令 怎么退出?
- MySQL 中decimal 的用法? 存儲(chǔ)小
- get 、set 、toString 方法的使
- @Resource和 @Autowired注解
- Java基礎(chǔ)操作-- 運(yùn)算符,流程控制 Flo
- 1. Int 和Integer 的區(qū)別,Jav
- spring @retryable不生效的一種
- Spring Security之認(rèn)證信息的處理
- Spring Security之認(rèn)證過濾器
- Spring Security概述快速入門
- Spring Security之配置體系
- 【SpringBoot】SpringCache
- Spring Security之基于方法配置權(quán)
- redisson分布式鎖中waittime的設(shè)
- maven:解決release錯(cuò)誤:Artif
- restTemplate使用總結(jié)
- Spring Security之安全異常處理
- MybatisPlus優(yōu)雅實(shí)現(xiàn)加密?
- Spring ioc容器與Bean的生命周期。
- 【探索SpringCloud】服務(wù)發(fā)現(xiàn)-Nac
- Spring Security之基于HttpR
- Redis 底層數(shù)據(jù)結(jié)構(gòu)-簡單動(dòng)態(tài)字符串(SD
- arthas操作spring被代理目標(biāo)對(duì)象命令
- Spring中的單例模式應(yīng)用詳解
- 聊聊消息隊(duì)列,發(fā)送消息的4種方式
- bootspring第三方資源配置管理
- GIT同步修改后的遠(yuǎn)程分支
 提供CDN加速
提供CDN加速