網站首頁 編程語言 正文
1.此處補充一下遷移學習,實際在比如構建一個圖像識別應用過程中,很少有人會直接隨機初始化權重,且很難有大量數據來重新訓練一個模型,相反的,我們會使用一個使用大批量數據訓練好的卷積神經網絡來訓練。早期的卷積層提取低級特征,往后的卷積層提取高級的特征。這意味著只要任務接近我們就可以添加少量的數據來微調,就可以實現任務的遷移。
2.循環卷積網絡受生物記憶啟發。RNN,此外RNN的加強版有LSTM,GRU。記憶力更強^^.
3.普通的神經網絡數據是單向傳遞的,而RNN是循環傳遞的,輸入x經過hidden得到y,而hidden的輸出結果h需要作為下次輸入的一部分,循環傳遞。
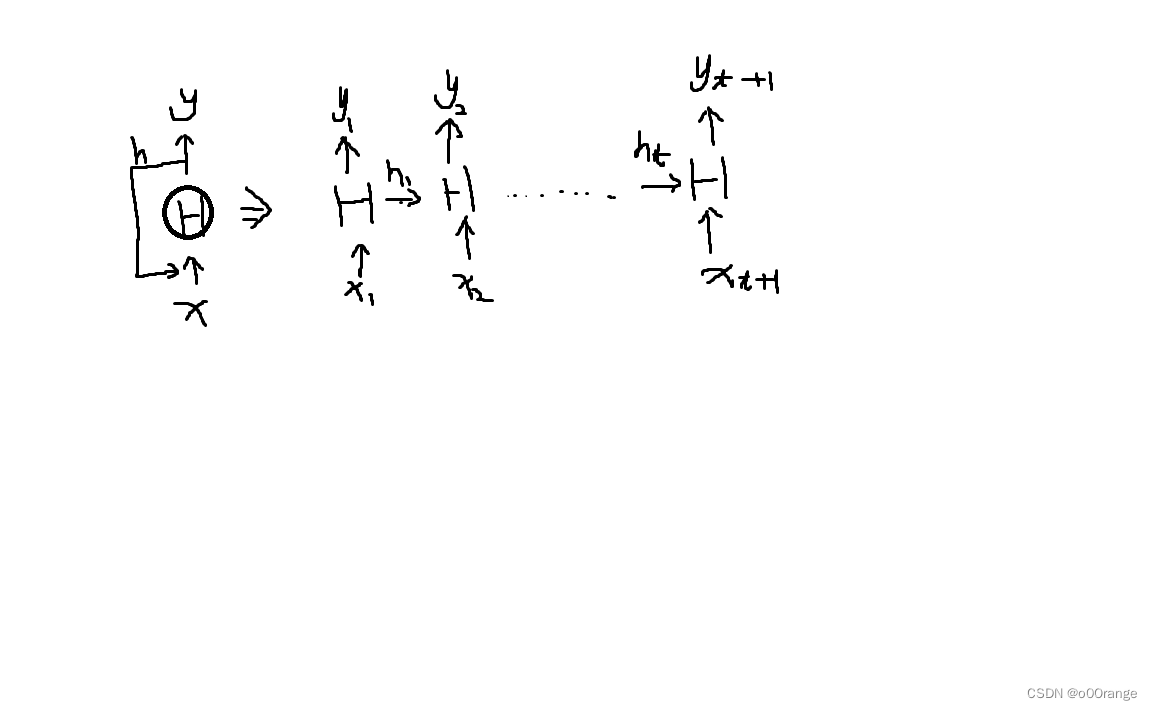
4.RNN的本質是tanh(xtht-1)
5.LSTM通過門來控制信息(記憶)的去留來解決梯度消失的問題
下面實現一個RNN讓三角函數sin去預測cos的值?
import numpy as np
import matplotlib.pyplot as plt
import torch
from torch import nn, optim
steps = np.linspace(0, np.pi*2, 100, dtype=np.float32)
input_x = np.sin(steps)
target_y = np.cos(steps)
plt.plot(steps, input_x, 'b-', label='input:sin')
plt.plot(steps, target_y, 'r-', label='target:cos')
plt.legend(loc='best')
plt.show()
# 定義一個LSTM
class LSTM(nn.Module):
def __init__(self,INPUT_SIZE):
super(LSTM,self).__init__()
self.lstm = nn.LSTM(
input_size=INPUT_SIZE,
hidden_size=20,
# 表示輸入輸出的第一維為batch_size
batch_first=True
)
self.out = nn.Linear(20,1)
# 隱藏向量h_state,c_state
def forward(self, x, h_state,c_state):
r_out,(h_state,c_state) = self.lstm(x,(h_state,c_state))
outputs = self.out(r_out[0,:]).unsqueeze(0)
return outputs,h_state,c_state
def InitHidden(self):
h_state = torch.randn(1,1,20)
c_state = torch.randn(1,1,20)
return h_state,c_state
lstm = LSTM(INPUT_SIZE=1)
optimizer = torch.optim.Adam(lstm.parameters(), lr=0.001)
loss_func = nn.MSELoss()
h_state,c_state = lstm.InitHidden()
plt.figure(1, figsize=(12,5))
plt.ion()
for step in range(600):
start, end = step*np.pi,(step+1)*np.pi
steps = np.linspace(start, end, 100, dtype=np.float32)
x_np = np.sin(steps)
y_np = np.cos(steps)
x = torch.from_numpy(x_np).unsqueeze(0).unsqueeze(-1)
y = torch.from_numpy(y_np).unsqueeze(0).unsqueeze(-1)
prediction,h_state,c_state =lstm(x, h_state,c_state)
h_state = h_state.detach()
c_state = c_state.detach()
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.plot(steps,y_np.flatten(), 'r-')
plt.plot(steps, prediction.data.numpy().flatten(),'b-')
plt.draw();plt.pause(0.05)
plt.ioff()
plt.show()
原文鏈接:https://blog.csdn.net/weixin_45650500/article/details/136116666
- 上一篇:沒有了
- 下一篇:沒有了
相關推薦
- 2023-10-18 下載文件時前端重命名的實現方法將url地址轉化為文件實現重命名
- 2023-04-04 C/C++關于實現CAN信號的獲取方法_C 語言
- 2022-09-05 Involution: Inverting the Inherence of Convolution
- 2022-04-10 element input輸入框千分位無法回顯問題解決方法
- 2022-08-02 C#如何使用Task類解決線程的等待問題_C#教程
- 2022-07-08 Python如何讀取csv文件時添加表頭/列名_python
- 2023-01-26 使用Jedis面臨的非線程安全問題詳解_Redis
- 2022-09-14 Python使用pip安裝Matplotlib的方法詳解_python
- 欄目分類
-
- 最近更新
-
- window11 系統安裝 yarn
- 超詳細win安裝深度學習環境2025年最新版(
- Linux 中運行的top命令 怎么退出?
- MySQL 中decimal 的用法? 存儲小
- get 、set 、toString 方法的使
- @Resource和 @Autowired注解
- Java基礎操作-- 運算符,流程控制 Flo
- 1. Int 和Integer 的區別,Jav
- spring @retryable不生效的一種
- Spring Security之認證信息的處理
- Spring Security之認證過濾器
- Spring Security概述快速入門
- Spring Security之配置體系
- 【SpringBoot】SpringCache
- Spring Security之基于方法配置權
- redisson分布式鎖中waittime的設
- maven:解決release錯誤:Artif
- restTemplate使用總結
- Spring Security之安全異常處理
- MybatisPlus優雅實現加密?
- Spring ioc容器與Bean的生命周期。
- 【探索SpringCloud】服務發現-Nac
- Spring Security之基于HttpR
- Redis 底層數據結構-簡單動態字符串(SD
- arthas操作spring被代理目標對象命令
- Spring中的單例模式應用詳解
- 聊聊消息隊列,發送消息的4種方式
- bootspring第三方資源配置管理
- GIT同步修改后的遠程分支
 提供CDN加速
提供CDN加速