網站首頁 編程語言 正文
【Redis】Redis中的布隆過濾器
前言
在實際開發中,會遇到很多要判斷一個元素是否在某個集合中的業務場景,類似于垃圾郵件的識別,惡意IP地址的訪問,緩存穿透等情況。類似于緩存穿透這種情況,有許多的解決方法,如:Redis存儲Null值等,而對于垃圾郵件的識別,惡意IP地址的訪問,我們也可以直接用 HashMap 去存儲惡意IP地址以及垃圾郵件,然后每次訪問時去檢索一下對應集合中是否有相同數據。這種思路對于數據量小的項目來說是沒有問題的,但是對于大數據量的項目,如:垃圾郵件出現有幾十萬,惡意IP地址出現有上百萬,那么這些大量的數據就會占據大量的空間,這個時候就可以考慮一下布隆過濾器了。
布隆過濾器是什么?
布隆過濾器(Bloom Filter)是1970年由布隆提出的。它實際上是一個很長的二進制向量和一系列隨機映射函數。布隆過濾器可以用于檢索一個元素是否在一個集合中。
可以把布隆過濾器理解為一個不怎么精確的 set 結構,當你使用它的 contains方法判斷某個對象是否存在時,它可能會誤判。但是布隆過濾器也不是特別不精確,只要參數設置得合理,它的精確度也可以控制得相對足夠精確,只會有小小的誤判概率。
當布隆過濾器說某個值存在時,這個值可能不存在;當它說某個值不存在時那就肯定不存在。打個比方,當它說不認識你時,肯定就是真的不認識;而當它說認識你時,卻有可能根本沒見過你,只是因為你的臉跟它認識的某人的臉比較相似(某些熟臉的系數組合),所以誤判以前認識你。
一句話總結:由一個初始值為零的bit數組和多個哈希函數構成,用來快速判斷集合中是否存在某個元素。
使用bit數組的目的就是減少內存的占用,數組不保存數據信息,只是在內存中存儲一個是否存在的表示0或1
布隆過濾器的優缺點:
優點:
? 高效插入和查詢,內存占用空間少
缺點:
- 存在誤判,不能精確過濾
- 不能刪除元素
布隆過濾器的使用場景
黑白名單校驗、識別垃圾郵件
發現存在黑名單中的,就執行特定操作。比如:識別垃圾郵件,只要是郵箱在黑名單中的郵件,就識別為垃圾郵件。假設黑名單的數量是數以億計的,存放起來就是非常耗費存儲空間的,布隆過濾器則是一個較好的解決方案。把所有黑名單都放在布隆過濾器中,在收到郵件時,判斷郵件地址是否在布隆過濾器中即可。
解決緩存穿透的問題
把已存在數據的key存在布隆過濾器中,相當于Redis前面擋著一個布隆過濾器。當有新的請求時,先到布隆過濾器中查詢是否存在:如果布隆過濾器中不存在該條數據則直接返回;如果布隆過濾器中已存在,才去查詢緩存Redis,如果Redis里沒查詢到則再查詢MySQL數據庫
布隆過濾器的原理
每個布隆過濾器對應到 Redis 的數據結構里面就是一個大型的位數組和幾個不-樣的無偏 hash函數,如下圖中的F、G、H就是這樣的hash函數。所謂無偏就是能夠把元素的 hash 值算得比較均勻,讓元素被 hash映射到位數組中的位置比較隨機。
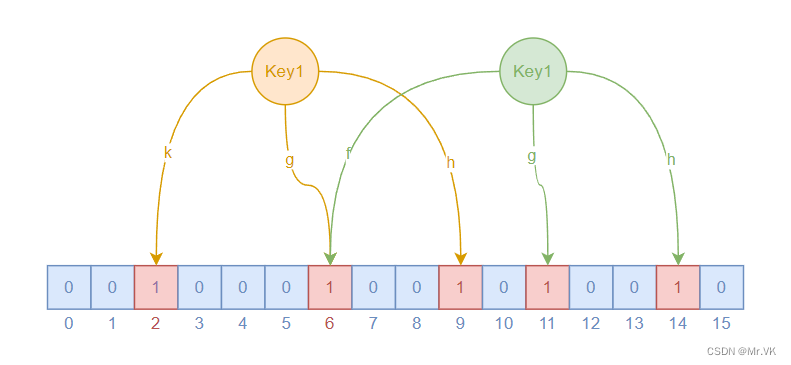
向布隆過濾器中添加 key 時,會使用多個 hash 函數對 key 進行 hash,算得一個整數索引值,然后對位數組長度進行取模運算得到一個位置,每個 hash 函數都會算得一個不同的位置。再把位數組的這幾個位置都置為 1,就完成了 add 操作。
向布隆過濾器詢問 key 是否存在時,跟add 一樣,也會把 hash 的幾個位置都算出來,**看看位數組中這幾個位置是否都為 1,只要有一個位為 0,那么說明布隆過濾器中這個 key 不存在。如果這幾個位置都是 1,并不能說明這個 key 就一定存在,只是極有可能存在,因為這些位被置為 1 可能是因為其他的 key 存在所致。**如果這個位數組比較稀疏,判斷正確的概率就會很大,如果這個位數組比較擁擠,判斷正確的概率就會降低。具體的概率計算公式比較復雜,感興趣可以閱讀相關的更深入研究的資料,不過非常燒腦,不建議讀者細看。
參考博客:Redis系列–布隆過濾器(Bloom Filter)_redistemplate 布隆過濾器_幼兒園里的山大王的博客-CSDN博客
基于Redisson的布隆過濾器使用實例
1.引入Redisson依賴
<!--原生-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4</version>
</dependency>
<!--或者另一種Spring集成starter-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.13.6</version>
</dependency>
2.配置Redisson
@Configuration
public class RedissionConfig {
@Value("${spring.redis.host}")
private String redisHost;
@Value("${spring.redis.password}")
private String password;
private int port = 6379;
@Bean
public RedissonClient getRedisson() {
Config config = new Config();
config.useSingleServer().
setAddress("redis://" + redisHost + ":" + port).
setPassword(password);
config.setCodec(new JsonJacksonCodec());
return Redisson.create(config);
}
}
3.配置布隆過濾器
@Configuration
public class BloomFilterConfig {
@Autowired
private RedissonClient redissonClient;
/**
* 創建訂單號布隆過濾器
* @return
*/
@Bean
public RBloomFilter<Long> orderBloomFilter() {
//過濾器名稱
String filterName = "orderBloomFilter";
// 預期插入數量
long expectedInsertions = 10000L;
// 錯誤比率
double falseProbability = 0.01;
RBloomFilter<Long> bloomFilter = redissonClient.getBloomFilter(filterName);
bloomFilter.tryInit(expectedInsertions, falseProbability);
return bloomFilter;
}
}
4.創建訂單表
CREATE TABLE `tb_order` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '訂單Id',
`order_desc` varchar(50) NOT NULL COMMENT '訂單描述',
`user_id` bigint NOT NULL COMMENT '用戶Id',
`product_id` bigint NOT NULL COMMENT '商品Id',
`product_num` int NOT NULL COMMENT '商品數量',
`total_account` decimal(10,2) NOT NULL COMMENT '訂單金額',
`create_time` datetime NOT NULL COMMENT '創建時間',PRIMARY KEY (`id`),
KEY `ik_user_id` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=51 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
5.編寫業務處理代碼
@Slf4j
@Service
public class OrderServiceImpl implements OrderService {
@Resource
private RBloomFilter<Long> orderBloomFilter;
@Resource
private TbOrderMapper tbOrderMapper;
@Resource
private RedisTemplate<String,Object> redisTemplate;
@Override
public void createOrder(TbOrder tbOrder) {
//1、創建訂單
tbOrderMapper.insert(tbOrder);
//2、訂單id保存到布隆過濾器
log.info("布隆過濾器中添加訂單號:{}",tbOrder.getId());
orderBloomFilter.add(tbOrder.getId());
}
@Override
public TbOrder get(Long orderId) {
TbOrder tbOrder = null;
//1、根據布隆過濾器判斷訂單號是否存在
if(orderBloomFilter.contains(orderId)){
log.info("布隆過濾器判斷訂單號{}存在",orderId);
String key = "order:"+orderId;
//2、先查詢緩存
Object object = redisTemplate.opsForValue().get(key);
if(object != null){
log.info("命中緩存");
tbOrder = (TbOrder)object;
}else{
//3、緩存不存在則查詢數據庫
log.info("未命中緩存,查詢數據庫");
tbOrder = tbOrderMapper.selectById(orderId);
redisTemplate.opsForValue().set(key,tbOrder);
}
}else{
log.info("判定訂單號{}不存在,不進行查詢",orderId);
}
return tbOrder;
}
}
6.單元測試
@Test
public void testCreateOrder() {
for (int i = 0; i < 50; i++) {
TbOrder tbOrder = new TbOrder();
tbOrder.setOrderDesc("測試訂單"+(i+1));
tbOrder.setUserId(1958L);
tbOrder.setProductId(102589L);
tbOrder.setProductNum(5);
tbOrder.setTotalAccount(new BigDecimal("300"));
tbOrder.setCreateTime(new Date());
orderService.createOrder(tbOrder);
}
}
@Test
public void testGetOrder() {
TbOrder tbOrder = orderService.get(25L);
log.info("查詢結果:{}", tbOrder.toString());
}
總結
布隆過濾器的原理其實非常簡單,就是bitmap + 多重hash,主要優勢就是利用非常小的空間就可以實現在大規模數據下快速判斷某一對象是否存在,缺點是存在誤判的可能,但不會漏判,也就是存在的對象一定會判斷為存在,而不存在的對象會有較低的概率為誤判為存在,且不支持對象的刪除,因為會增加誤判的概率。最典型的使用是解決緩存穿透的問題。
原文鏈接:https://blog.csdn.net/Mr_VK/article/details/132385485
- 上一篇:沒有了
- 下一篇:沒有了
相關推薦
- 2022-05-15 python數字類型和占位符詳情_python
- 2022-06-12 Python使用matplotlib.pyplot?as?plt繪圖圖層優先級問題_python
- 2022-03-19 Linux系統下安裝Redis數據庫過程_Redis
- 2022-04-12 用python繪制極坐標雷達圖_python
- 2022-12-12 用C語言如何打印一個等腰三角形_C 語言
- 2022-07-02 C語言由淺入深理解指針_C 語言
- 2022-06-19 Rainbond云原生快捷部署生產可用的Gitlab步驟詳解_云其它
- 2022-06-24 Go單體服務開發最佳實踐總結_Golang
- 欄目分類
-
- 最近更新
-
- window11 系統安裝 yarn
- 超詳細win安裝深度學習環境2025年最新版(
- Linux 中運行的top命令 怎么退出?
- MySQL 中decimal 的用法? 存儲小
- get 、set 、toString 方法的使
- @Resource和 @Autowired注解
- Java基礎操作-- 運算符,流程控制 Flo
- 1. Int 和Integer 的區別,Jav
- spring @retryable不生效的一種
- Spring Security之認證信息的處理
- Spring Security之認證過濾器
- Spring Security概述快速入門
- Spring Security之配置體系
- 【SpringBoot】SpringCache
- Spring Security之基于方法配置權
- redisson分布式鎖中waittime的設
- maven:解決release錯誤:Artif
- restTemplate使用總結
- Spring Security之安全異常處理
- MybatisPlus優雅實現加密?
- Spring ioc容器與Bean的生命周期。
- 【探索SpringCloud】服務發現-Nac
- Spring Security之基于HttpR
- Redis 底層數據結構-簡單動態字符串(SD
- arthas操作spring被代理目標對象命令
- Spring中的單例模式應用詳解
- 聊聊消息隊列,發送消息的4種方式
- bootspring第三方資源配置管理
- GIT同步修改后的遠程分支
 提供CDN加速
提供CDN加速